Un modelo de base de datos según su utilidad
Para Powell (2006) una base de datos usa cómputo para alojar "una gran colección de información organizada, recuperable". Así mismo, una base de datos relacional es aquella que guarda datos en tablas. Eso permite organizar datos en columnas y filas, con relaciones y dependencias organizadas con lógica.
En cambio, un modelo de base de datos es una plantilla diseñada (o conjunto de criterios) que organiza datos (e impone reglas en cómo serán o no organizados), o editados, o relacionados, o actualizados controladamente según una necesidad única y dentro de una gran base de datos.
Un modelo de base de datos responde a las siguientes preguntas:
- ¿Qué tipos de entidades (grupos de datos) existen?
- ¿Cómo se relacionan?
- ¿Qué operaciones son válidas sobre ellas?
- IMPORTANTE:¿Qué dato depende de qué otro dato?
- IMPORTANTE:¿Cuál es el dato padre (dato determinante) y cuál es el dato hijo (dato dependiente)?
Así mismo, la relación entre los datos debe mantener una dependencia lógica sencilla, que no requiera una gran cadena de datos para comprender qué dato depende de cuál otro. Por eso es necesario comprender desde ya los tipos de dependencias.
Identificarlas desde ya será útil a futuro porque cada dependencia podría ser necesaria (o tener que evitarse por completo) según el contexto de cada tabla y sus datos.
Pero entonces, ¿Cuál dependencia es la mejor y la más óptima? aquella en la que en un registro vincula única y directamente un solo identificador irrepetible con un valor de atributo. Puesto que no podremos evitar todas las relaciones entre datos, siempre deberemos intentar simplificar esas relaciones al modo ID-único -> dato.
Las siguientes explicaciones se tomaron de Powell (2006, p. 77-80).
Dependencia funcional: ocurre cuando el valor de un atributo (por ejemplo, del atributo ID) determina de manera única el valor de otro atributo. En el ejemplo de abajo, el código 001 determina a Romero y a su vez a Eduardo (los identifica). Pero esa dependencia no ocurre al revés, pues el apellido Romero con el ID 002 vincula a otro nombre diferente.
Ejemplo de atributos de columna y valores de campos
ID-----APELLIDO---NOMBRE
001----Romero-----Eduardo
002----Romero-----Heinz
Determinante: el atributo (o conjunto de atributos) que determina de forma precisa y única a otro atributo. En el ejemplo de arriba, el ID identifica sin ambigüedades al resto de datos.
Dependencia transitiva: cuando un atributo depende indirectamente de otro mediante un tercer atributo. En el ejemplo de abajo, el valor del atributo ID conduce (con lógica) al valor del atributo CIUDAD y estos a su vez a los valores del atributo PAÍS. Puesto que es lógico que, para cada país, le corresponde una ciudad capital.
Ejemplo de atributos de columna y valores de campos
ID-----CAPITAL----PAIS
001----Berlin-----Alemania
002----Guayaquil--Ecuador
Dependencia funcional completa: Cuando un grupo de atributos (llamado clave compuesta) conduce con lógica y exactitud a determinar el valor de otro atributo. En el ejemplo de abajo, el conjunto de ID, APELLIDO y CURSO conducen de forma exacta al valor del atributo NOTA. Puesto que únicamente el ID por sí solo no bastaría, ya que muchos estudiantes estarían en uno o más cursos. La dependencia funcional aclara si un dato requiere más de un atributo para identificarlo con exactitud, sin ambigüedad. Como veremos luego, un dato aislado no representa realmente información.
Ejemplo de atributos de columna y valores de campos
ID----APELLIDO----CURSO---NOTA
01----Safadi------Letras---09
02----Olmedo------Poesía---10
03----Jaramillo---Música---9.7
Por ejemplo, no es lo mismo administrar una gigante base de datos, como la del Municipio de Guayaquil. Eso requiere alojar nombres, direcciones y pagos de miles de usuarios en tiempo real (exige integridad –no deben repetirse datos– y seguridad -no deben ser accesibles o alterados por terceros–, además de actualizaciones en línea y respuesta inmediata en las consultas).
En contraste con una base de datos que solo requiere guardar el puntaje (transaccional, con menos concurrencia -menos usuarios al mismo tiempo haciendo lo mismo–) en un sencillo videojuego instalado en mi celular.
Ya expliqué en esta sección algunos tipos de modelos de bases de datos. Los resumo aquí:
- De archivo simple (como en los formatos de archivos .csv) donde los datos tan solo estan separados por comas.
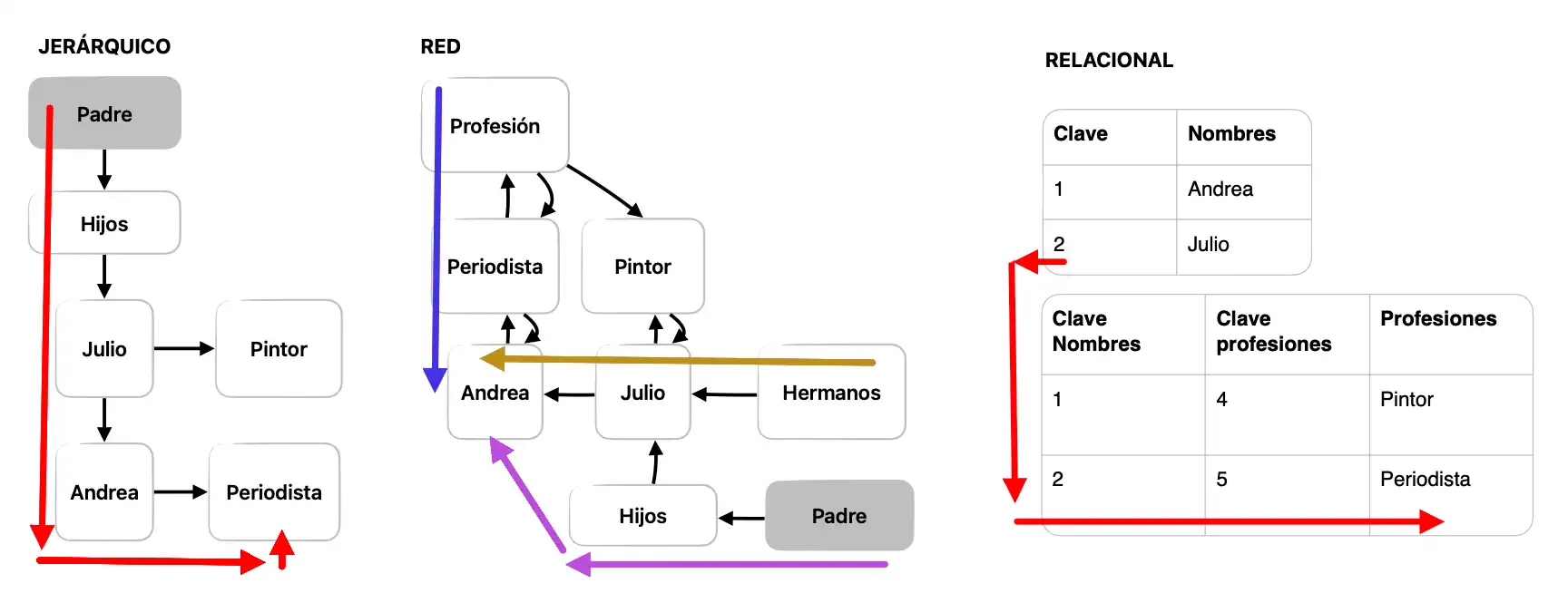
- Modelo de base de datos jerárquico (con los datos ramificados y conectados de arriba hacia abajo, según su descendencia de mayor -dato padre- a menor -dato hijo-). El problema con ese modelo es que existe una sola ruta para hallar un dato.
- Modelo en red (los mismos datos ramificados, conectados o relacionados entre sí mediante enlaces previamente diseñados), pero esta vez pueden ser accedidos desde distintas rutas y no solamente por la descendencia de arriba hacia abajo.
- Modelo de objeto, según Powell (2006, p. 12) refiere a una estructura tridimensional de datos, permitiendo diferentes puntos de ubicación o de ingreso para hallar un dato único. El problema con este modelo es que los datos no siempre estan vinculados entre sí (como en el modelo relacional), por lo que hallar más de un dato es muy complejo con el modelo de objeto .
- Modelo relacional, en forma de tablas con campos de datos conectados según un dato único compartido entre esas tablas. En este modelo un dato muy anidado a profundidad es mejor accedido tan solo ubicando otro dato relacionado directamente.
En otras palabras, ya que diferente software (como un videojuego o la base de datos del Municipio de Guayaquil, por ejemplo) alojan datos según su capacidad y posibilidad de uso, existirá un modelo diferente de base de datos para cada plataforma. Es decir, cada modelo de base de datos se diseña según cómo será accedido por los usuarios.
Diseñando desde las relaciones de los datos
Diseñar desde las relaciones de los datos significa aclarar cuál es la secuencia real que provoca la existencia de un dato antes de ser insertado en una tabla de datos.
Por ejemplo, si una librería necesita enlistar los libros que venderá, es muy posible que en este año 2026 un autor solo haya publicado un libro; o que ya tenga publicado muchos libros; o que el mismo autor no tenga publicado ningún libro este año.
Si bien solo el autor estará en la lista, el flujo del negocio de una librería depende de la cantidad de libros publicados por uno o muchos autores. Una librería nunca podría vender libros que no existan. Por lo que los datos a ingresar deben regirse bajo un criterio de integridad.
Así mismo, más de un autor podría tener un mismo nombre o un mismo apellido. O sus libros podrían tener similar título, pero con diferente año de publicación o con más de un colaborador en la obra. El desafío de diseñar desde las relaciones de los datos es evitar que los datos se solapen o se reescriban. Lo óptimo es que cada fila represente un hecho, y cada columna (cada atributo) represente una característica de ese hecho.
Lo óptimo es que cada fila (cada registro) represente un hecho y cada columna (cada atributo) represente una característica de ese hecho.
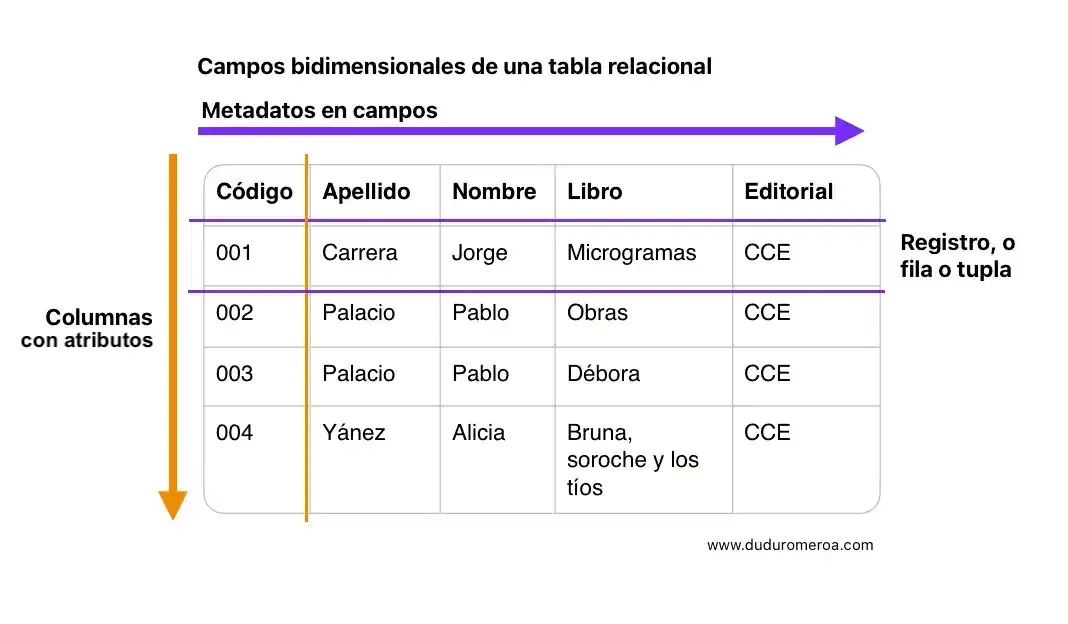
Tipos de datos
Los tipos de datos definen qué especie de dato es permitido para cada campo (y cuál no se permite). Por lo que funcionan como un filtrado para cada dato de cada campo. Por ejemplo, los datos ingresados para cada registro en el campo Código únicamente deben ser numéricos enteros sin decimales (a menos que se indique lo contrario).
Otro tipo de dato son los caracteres alfanuméricos (o strings, en la jerga técnica). Durante el diseño de la tabla es posible indicar la extensión máxima de cada tipo de dato.
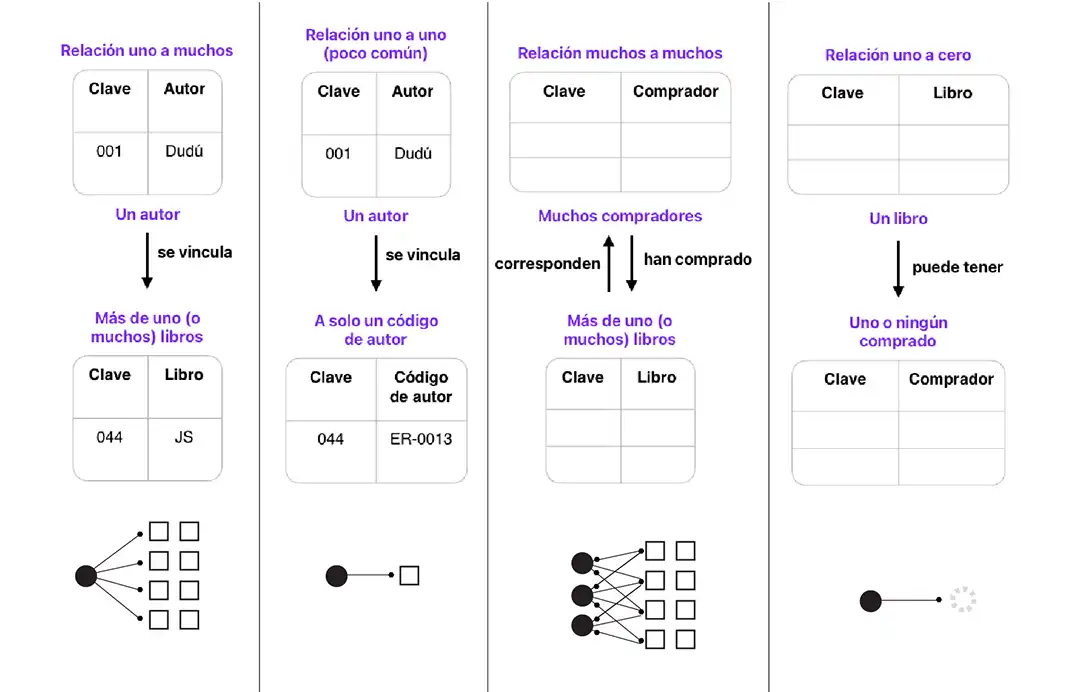
Representar relaciones en una tabla relacional
Como ya explicamos, las bases de datos deben abstraer lo que ocurre en la vida real. En el ejemplo de una librería vimos que es posible que uno o más autores hayan publicado uno o muchos libros. Esas dimensiones (uno, muchos; o muchos a muchos; o cero a uno, etc.) se convierten en relaciones entre dos o más tablas que deben ser expuestas.
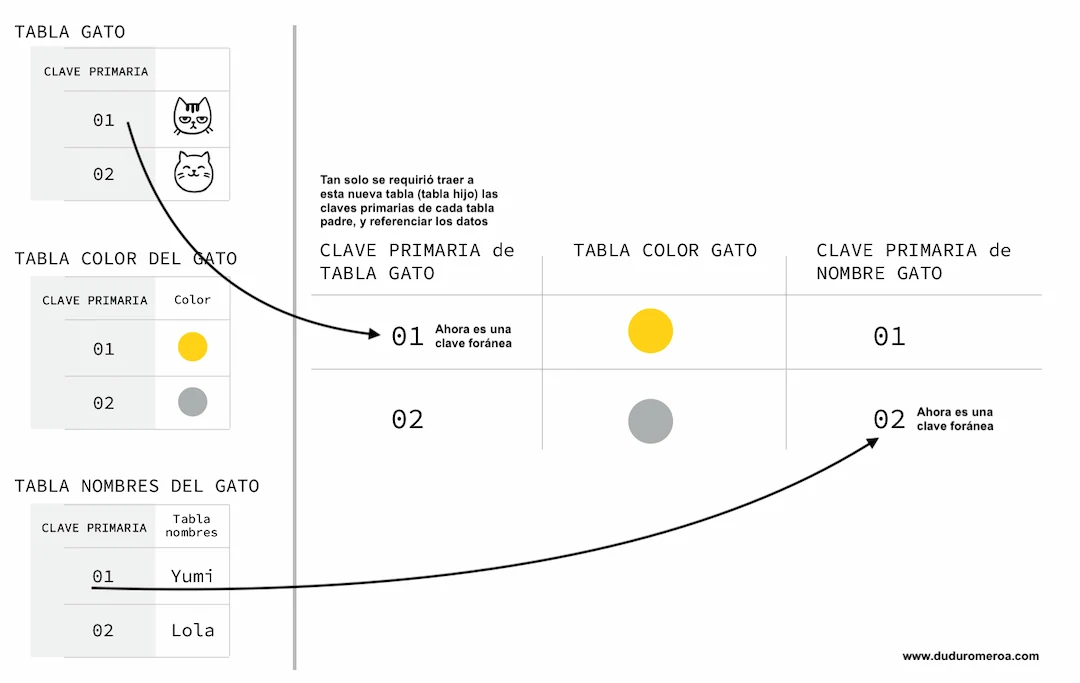
Claves o índices (keys en inglés)
Una clave es un identificador numérico y secuencial para cada fila o tupla, similar a un número de cédula para un ciudadano. La clave (o índice) es irrepetible (aunque algunos de los campos tengan datos repetidos). La clave va vinculada a una fila de datos y (lo más importante) sirve como identificador de enlace en otros grupos de datos (en este caso, tablas).
Existen tres tipos de claves (o de índices, o de keys): Clave primaria, clave foránea y clave única.
- Clave primaria: Es única e identifica a una única fila o tupla de datos. Es usada para crear relaciones entre tablas.
- Clave única: lo es porque no se repite. No toda clave única es clave primaria.
- Clave foránea: Es la copia de una clave primaria que inició en una tabla-padre y luego es alojada en otra tabla-hijo. La clave foránea crea una relación inter-tabla, referenciando fila con otros datos.
- Cuando una clave primaria es aprovechada para vincular datos en una nueva tabla, entonces esa primaria se convierte en foránea.
En el ejemplo de abajo, las claves primarias de las tres primeras tablas nos permiten responder (desde la nueva tabla más grande) a la pregunta de ¿Cuál es el nombre del gato amarillo y qué expresión tiene? La respuesta: Al gato serio y se llama Yumi.
Siguiente artículo: Capítulo 2, normalizaciones 1NF, 2NF, 3NF
Reseña de bases de datos y lenguaje SQL en programación.