Bases de datos tipos, modelos y estructura de una tabla relacional
En la anterior sección vimos una introducción a las condiciones de una base de datos, la diferencia entre modelos de base de datos y bases de datos como tal, estructura de las tablas, tipos de datos y uso de índices (o claves, locales y foráneas).
Creación de índices (claves primarias -CP- y foráneas -CF-)
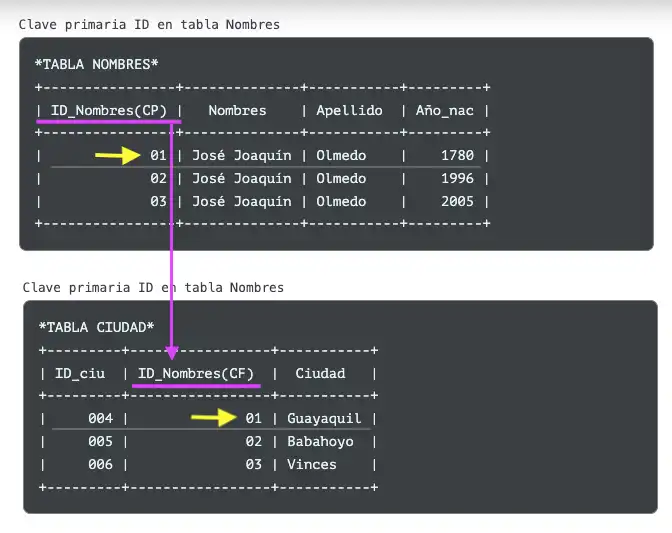
Vimos que un índice de tabla es un identificador numérico único y secuencial para cada fila de la tabla. Tan importante es, que da certezas incluso cuando existen datos casi idénticos. De aquí en adelante indicaré como una clave (primaria o foránea, ya explicaré eso luego) cuando se trate de un índice en tablas relacionales. En el ejemplo de abajo, la tabla Nombres inicia con un atributo (nombre de columna) ID_Nombres, que es clave primaria para cada fila de esa tabla.
Clave primaria ID en tabla Nombres
*TABLA NOMBRES*
+----------------+--------------+-----------+---------+
| ID_Nombres(CP) | Nombres | Apellido | Año_nac |
+----------------+--------------+-----------+---------+
| 01 | José Joaquín | Olmedo | 1780 |
| 02 | José Joaquín | Olmedo | 1996 |
| 03 | José Joaquín | Olmedo | 2005 |
+----------------+--------------+-----------+---------+
Lo mágico de una clave primaria es su conversión a clave externa (o foránea, identificada como CF) cuando necesitamos relacionar tablas. Ahora, en esta segunda tabla, vamos a vincular la tabla anterior a la que agregamos una clave foránea ID_Nombres(CF) (extaída de la tabla anterior).
Entre otras funciones, esa clave foránea ID_Nombres(CF) nos permite vincular datos intertablas. Así podemos responder a preguntas como ¿En qué ciudad nació el ciudadano José Joaquín de Olmedo en el año 1780?. Si deseas otro ejemplo, puedes acceder acá a uno con gatos.
Clave primaria ID en tabla Nombres
*TABLA CIUDAD*
+---------+-----------------+-----------+
| ID_ciu | ID_Nombres(CF) | Ciudad |
+---------+-----------------+-----------+
| 004 | 01 | Guayaquil |
| 005 | 02 | Babahoyo |
| 006 | 03 | Vinces |
+---------+-----------------+-----------+
Hay más de una forma de definir claves: ordenables (de mayor a menor), únicos (nunca repetidos), no-únicos (permiten tener valores repetidos), compuestos (creado desde múltiples columnas) y comprimidos. Solo cuando sea necesario explicaré una o más de esas definiciones.
Normalización de modelos de bases de datos
El contenido de una base de datos podría corromperse, por ejemplo, al borrar por error un registro hijo (con sus claves foráneas) pero no borrar el registro padre (con sus claves primarias); ingresar un dato en el orden incorrecto o una fecha desactualizada o un dato repetido.
Normalizar se refiere a corregir o ajustar una relación artificial entre hechos, medido en dependencias erróneas o que no se ajustan a la realidad. En el ámbito de las bases de datos (BD) es el ejercicio de eliminar duplicados y datos redundantes en las tablas para así optimizar consultas (Powell, 2006, p. 102). La normalización es un método de mejoras.
Para Powell (2006) los métodos de normalización (que se enumeran en la forma 1NF –Normal Form–, 2NF, 3NF, hasta 5NF) se resumen con sentido común en lo siguiente: lo óptimo es que cada registro de tabla debe identificarse con una sola clave, evitar dependencias parciales (cuando un campo depende solamente de un valor) y transitivas (cuando un campo depende de otro valor que a su vez depende de una clave).
¿Qué significa dependencia en una base de datos relacional?
Para explicarlo en letras, B depende de A cuando A primero existe; entonces luego B existe.
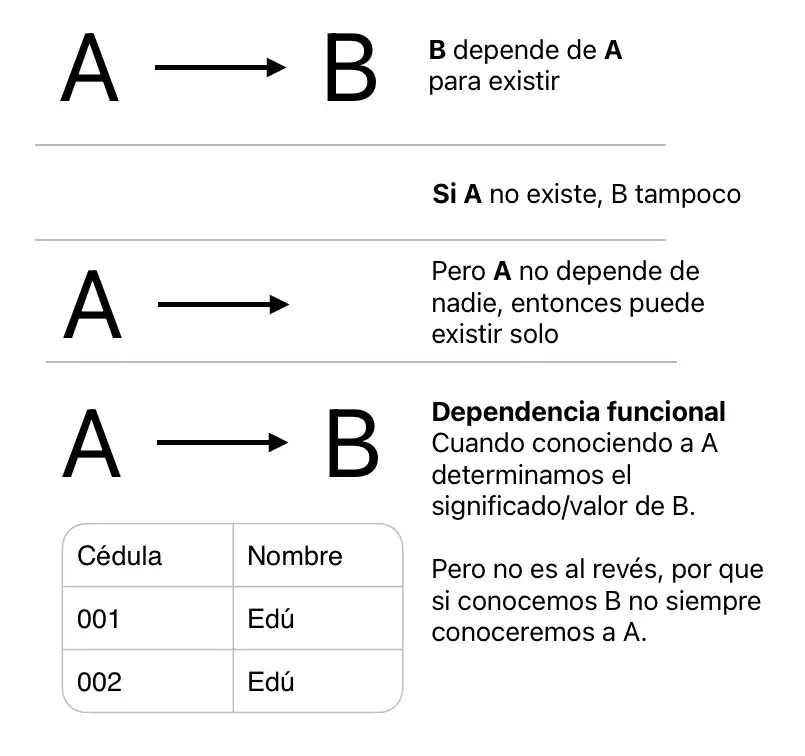
Recordemos esto: en diseño de base de datos, relaciones excesivas ocasionarán (a futuro) un problema de mantenimiento y de rendimiento en nuestra base de datos.
Por lo tanto, el mejor criterio de normalización es aquel que, durante el diseño de las relaciones, nos evita crear demasiadas tablas para definirlas. Recordemos esto: en diseño de base de datos, relaciones excesivas ocasionarán (a futuro) un problema de mantenimiento y de rendimiento en nuestra base de datos.
Normalización primera 1NF (normalization form en inglés)
Para Powell (2006, p. 81) 1NF elimina los campos repetidos creando (desde una tabla padre) dos tablas hijo vinculadas en una relación uno a muchos. Es decir, si conozco uno de los campos, entonces conoceré los demás campos.
Ejemplo de NO normalización en tabla
*TABLA BANDAS*
+---------+-----------+---------+--------------+
| Banda | Miembros | Género | Álbumes |
+---------+-----------+---------+--------------+
| Broca | 4 | punk | Somos uno |
| Broca | 4 | punk | Rockeros |
| Broca | 4 | punk | Cabeza punk |
| Broca | 4 | punk | Exitos |
| Mojitos | 2 | jazz | Guayacos |
| Mojitos | 2 | jazz | Súper Éxitos |
| Vibora | 5 | pop | Rojo Puro |
| Vibora | 5 | pop | Hermandad |
| Vibora | 5 | pop | Noche vibora |
| Vibora | 5 | pop | Nueva Mente |
+---------+-----------+---------+--------------+
En el ejemplo de arriba (una tabla no normalizada) la redundancia es clara. Existe una realidad (la realidad a modelar mediante una tabla) es que muchas bandas musicales pueden tener más de un álbum (o ninguno aún). ¿Por qué no es óptima? La razón: en la misma tabla conviven dos atributos: Banda y Álbumes (es decir, una relación de uno a muchos, como ya se explicó en esta sección.).
Y ya que la banda Broca tiene cuatro álbumes, entonces Broca se repetirá (en esa tabla) cuatro veces, como se ve en la tabla de ejemplo. ¿Es óptima esa redundancia? No, pues esa redundancia está afectando otros atributos (es decir, nombres de filas) al repetir datos de los atributos (nombre de las columnas Miembros y Género).
¿Por qué es un problema la duplicación (la redundancia) de datos en una tabla?
- Más almacenamiento, más escritura, más mantenimiento
- Más posibilidad de inconsistencias: si luego actualizamos que Broca tiene 8 miembros, entonces deberemos actualizar cada fila. Si por error dejamos de actualizar una, entonces ¡habrán fallos y contradicciones!.
- Entonces: ¿cuántos miembros tiene Broca? habría dos respuestas y no sabremos cuál es la correcta. ¿Y si Broca cambia de género musical con el pasar de los años? Lo mismo, deberíamos actualizar cada campo del atributo Género.
- Anomalía de inserción: Ojo, en esa tabla cada registro necesita los atributos Banda, Miembros, Género y Álbumes. Si deseo ingresar a una nueva banda, estoy obligado a ingresar en todos los atributos. ¿Y si esa nueva banda aún no tiene álbum?
- Anomalía de eliminación: Si en la tabla de arriba debo eliminar un álbum de una de las bandas, entonces deberé eliminar el resto de atributos (nombres de columnas) de la fila correspondiente.
¿Cómo resolver esas redundancias? Para Powell (2006) la normalización 1NF "elimina los campos repetidos creando una nueva tabla donde la tabla original (padre) y la nueva (hijo) están vinculadas en una relación de detalle maestro. Ojo como las claves ID (número único e irrepetible que representa cada fila) se extrapolan en forma de claves foráneas hacia la tabla hijo (tabla Álbumes).
¿Cómo son aprovechadas las claves primarias y las foráneas? En la tabla Bandas (tabla padre) cada fila de datos tiene un ID_Banda⭐. Es decir, en esta tabla a la banda Broca le corresponde el ID 1, a Mojitos el ID 2, etc.
Luego, a la nueva tabla Álbumes (tabla hijo) le insertamos un atributo de la tabla Bandas. Ese atributo (nombre de la columna) a insertar es ID_Bandas. Pero en la nueva tabla la renombramos como ID_Banda (CF)✅. Recordemos: CF significa clave foránea.
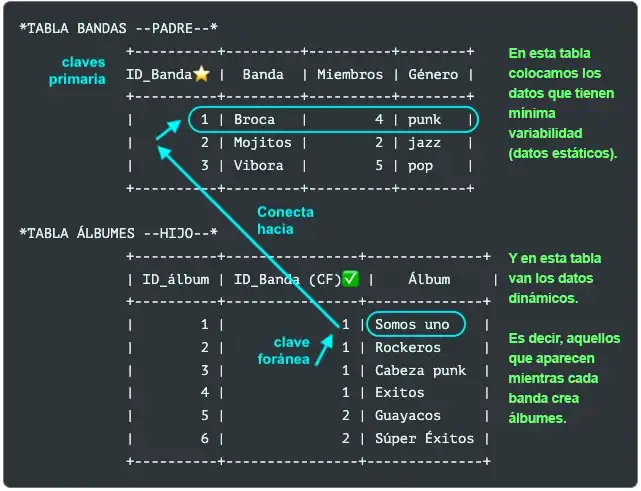
¿En qué ayuda el atributo (la columa) de clave foráneas (CF) en la segunda tabla? Nos ayuda a vincular datos entre otras tablas. En la segunda tabla ya no repetimos demasiados atributos (nombres de columnas) para un solo nombre de banda. Es decir, si preguntamos ¿El álbum 'Somos uno' a qué banda pertenece? La respuesta estará en su clave primaria (CP) ID_Banda número 1; que a su vez conecta con el ID_banda de la tabla Bandas.
En resumen, ahora la organización de datos es más óptima porque no hay redundancias y además existen relaciones (desde las claves primarias con las foráneas) en modo intertablas.
Normalización segunda 2NF
Para Powell (2006, p. 89) se resumen en:
- La tabla debe haber sido ser normalizada en 1NF
- Todos los valores de campos que no son claves primarias deben ser dependientes de la clave principal.
- Separar datos estáticos de los transaccionales:
- Datos estáticos: Aquellos que no cambian a lo largo del tiempo en la vida real, como un título de un libro ya publicado, el nombre de un autor o el género literario de un libro
- Datos transaccionales: Aquellos que cambian con el tiempo a lo largo de la vida real. Por ejemplo, fechas de venta, cantidad de items, número de factura, ID de clientes.
Normalización tercera 3NF
Se resume en lo siguiente:
- Las tablas deben haber sido normalizadas en 2NF.
- Ningún atributo NO clave debe depender de otro atributo NO clave. Lo óptimo es que un atributo no clave debe depender de uno clave (como una clave primaria).
- Eliminar dependencias transitivas: Una dependencia transitiva (
Si A → B → C entonces A → C) ocurre cuando un atributo no clave depende de otro atributo no clave, en lugar de depender directamente de la clave primaria. -
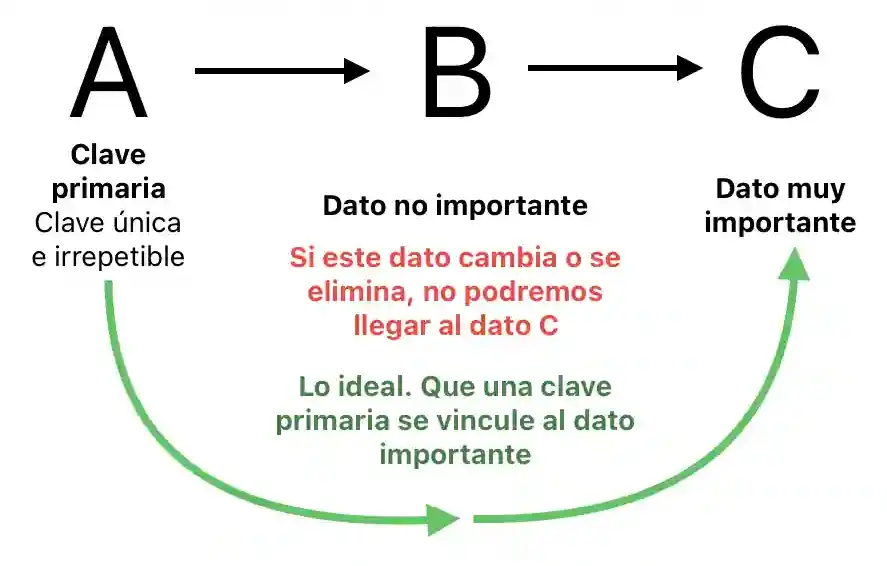
Para explicar lo anterior: Supongamos que la siguiente tabla contiene 500 empleados (y no solo tres).
Allí ocurre la dependencia transitiva que la 3NF desea evitar. El atributo ciudad depende del ID del empleado (es decir, primero debe existir Empleado para que exista Ciudad). En la vida real las oficinas pueden cambiar de ciudad y los empleados renuncian o nuevos son contratados. Si una oficina cambia, deberemos hacer 500 (o más) actualizaciones de ciudad de cada empleado.
O peor, si por error de click borramos a Pedro (y su ID) no podremos saber qué ciudad vincula a Costos. El error conceptual (y que nos lleva a modelar una realidad errónea) está en esta afirmación explícita en esta tabla: 'existe una ciudad porque existe un departamento'. Cuando lo que realmente ocurre (de nuevo, en la vida real) es que existe un departamento independientemente de los empleados, y son estos los que dependen (pertenecen) a un departamento.
Tabla de 500 empleados sin normalización
+-------------+----------+--------+--------+
| ID_Empleado | Empleado | Depto. | Ciudad |
+-------------+----------+--------+--------+
| 001 | Julio | Ventas | Gye |
| 002 | Ana | Ventas | Gye |
| 003 | Pedro | Costos | Gye |
+-------------+----------+--------+--------+
¿Cómo resolver esa dependencia transitiva? ahora explícitamente afirmamos que "Los departamentos existen independientemente. Los empleados pertenecen a ellos." Y aprovechamos el vínculo de la clave foránea ID_dpto en la tabla Empleados. Notemos cómo esta única clave ID_dpto permite responder a las preguntas: ¿Julio en qué departamento está y en qué ciudad?, ¿El departamento de Bodega en qué ciudad queda y qué empleado tiene?.
Tabla de 500 empleados con 3NF
*TABLA DPTOS*
+---------+---------+--------+
| ID_dpto | Depto | Ciudad |
+---------+---------+--------+
| 010 | Ventas | Gye |
| 011 | Costos | Uio |
| 012 | Bodega | Gye |
+---------+---------+--------+
*TABLA EMPLEADOS.*
+-------------+----------+---------+
| ID_empleado | Empleado | ID_dpto |
+-------------+----------+---------+
| 001 | Julio | 010 |
| 002 | Ana | 011 |
| 003 | Pedro | 012 |
+-------------+----------+---------+
En resumen, las normalizaciones van un poco más allá de 3NF. Aunque se recomienda no pasar de 3NF en tablas de complejidad intermedia, debemos recordar que a más normalización (resultando en más cantidad de tablas con datos únicos) más datos específicos en las tablas (llamado granulación) pero también mayor complejidad en las relaciones intertablas.
Si deseas profundizar más allá de 3NF recomiendo revisar en otras fuentes la Boyce-Codd Normal Form (BCNF), 4NF, 5NF, forma normal de la clave de dominio (Domain Key Normal Form, DKNF). Métodos que no se explicarán acá por ser necesarios en ámbitos de mayor complejidad en datos.
Siguiente artículo: Sección 3, codificación con SQL
Estudio de bases de datos relacionales.